Types of network topologies
We live in times, where each day more and more data is created …
As Professor Melvin M. Vopson from the University of Portsmouth estimates, by the end of 2025, their volume will achieve the incredible value of 175 ZB (Zetabyte; 1ZB≈1012 GB). It is an amazing fact, taking into consideration research, which indicate that 90% of this data
we have created in the last two years.
No wonder then that natural result of this situation developed the need of effective transforming and visualizing gathered data
and management gained knowledge. And even it seems that this case is mostly connected with business side, it is also present everywhere, where you have a chance to work in a group – especially when you collaborate in an interdisciplinary team, when exchange of core information through members is a daily routine to meet the targets.
In this scenario, we focus more on three types of different ways to make connections in networks,
and we try to describe pros and cons of each of them.
The first presented method, we are involved every day in our social networks, is the centralized one. This kind of connection focus knowledge in one specific node in a network. A person who is in the centre of this connection can be constituted as the field experts who well-know the study case, serving as a source of knowledge for less experienced employees. However, he or she is also crucial for the right organization operations and if they are too much burden with the responsibilities from e.g. other employees,
they are not able to do their duties in an effective way. So, it is important to keep the balance between the centralized node (expert)
and the number of connections (employees), who can rely on them, using their knowledge.
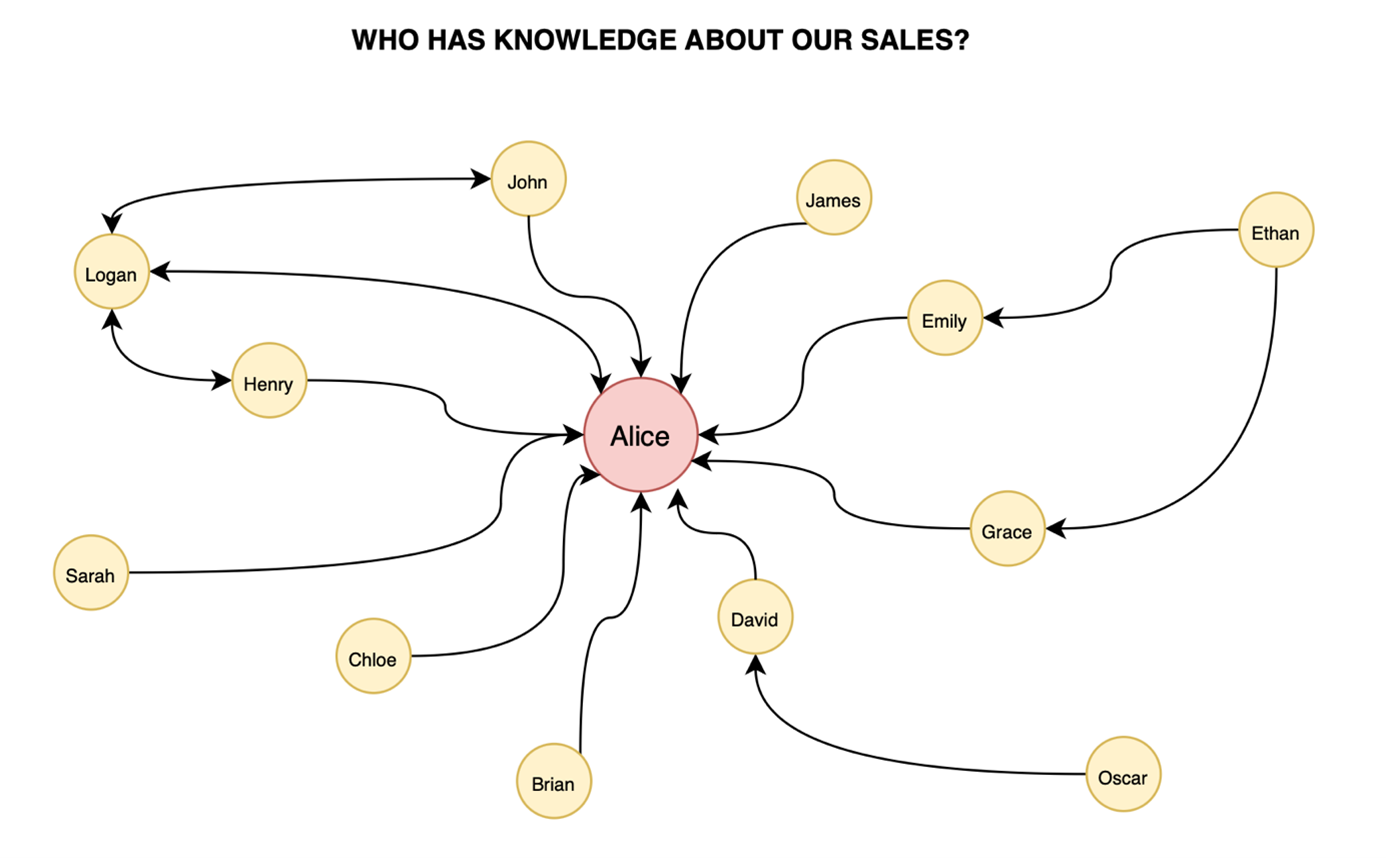
Fig. 1 An example of a centralized network, where Alice is main, the most crucial node
and other employees can base on her knowledge
Source: Own elaboration
On the other hand, in some kinds of organizations, we can also observe completely different from previously described solution, attitude to knowledge management system, which takes the form of a decentralized network. As you can guess, this type of network
is the total opposite of the centralized one. It means that knowledge is created, stored and passed through different nodes in network. Moreover, there is usually no main node, but knowledge is more diversified through employees, who do not rely on only one person
but exchange their learning during everyday tasks. It is worth adding that this method can allow independent organization from situation where e.g. employee, who has all the most important knowledge is sick and we do not have any replacement to ensure continuity
of work in our enterprise. Nevertheless, we must also remember that decentralized knowledge management carries the risk of using incorrect or even conflicting information derived from different sources. So, this scenario demands taking into mind the great role
of checking and coordination of knowledge.

Fig. 2 An example of a decentralized network, where each employee has some information on a given topic
and knowledge is freely shared through the organisation
Source: Own elaboration
The last method of basic connection nodes in a network is the modular one. We can understand this kind of management knowledge
in an organisation, as the connection between centralized and decentralized network -the result gained by connectivity
of their positive features. As previous, knowledge is also divided, but in this specific case, its management is implemented through exchange of information between groups organized into modules. Each module is autonomic and has their own “piece of crucial information”, which through cooperation and connection with other teams allows them to meet the organization requirements smoothly. It is important also to point out that in the modular strategy, different from centralized method, there is not also an obligation to organize knowledge into one main node. Of course, they can be something like “superior node” which will take care of knowledge gained
in modules - but their main role in this scenario, is more as an advisory body, supporting other network parts in the information flow.
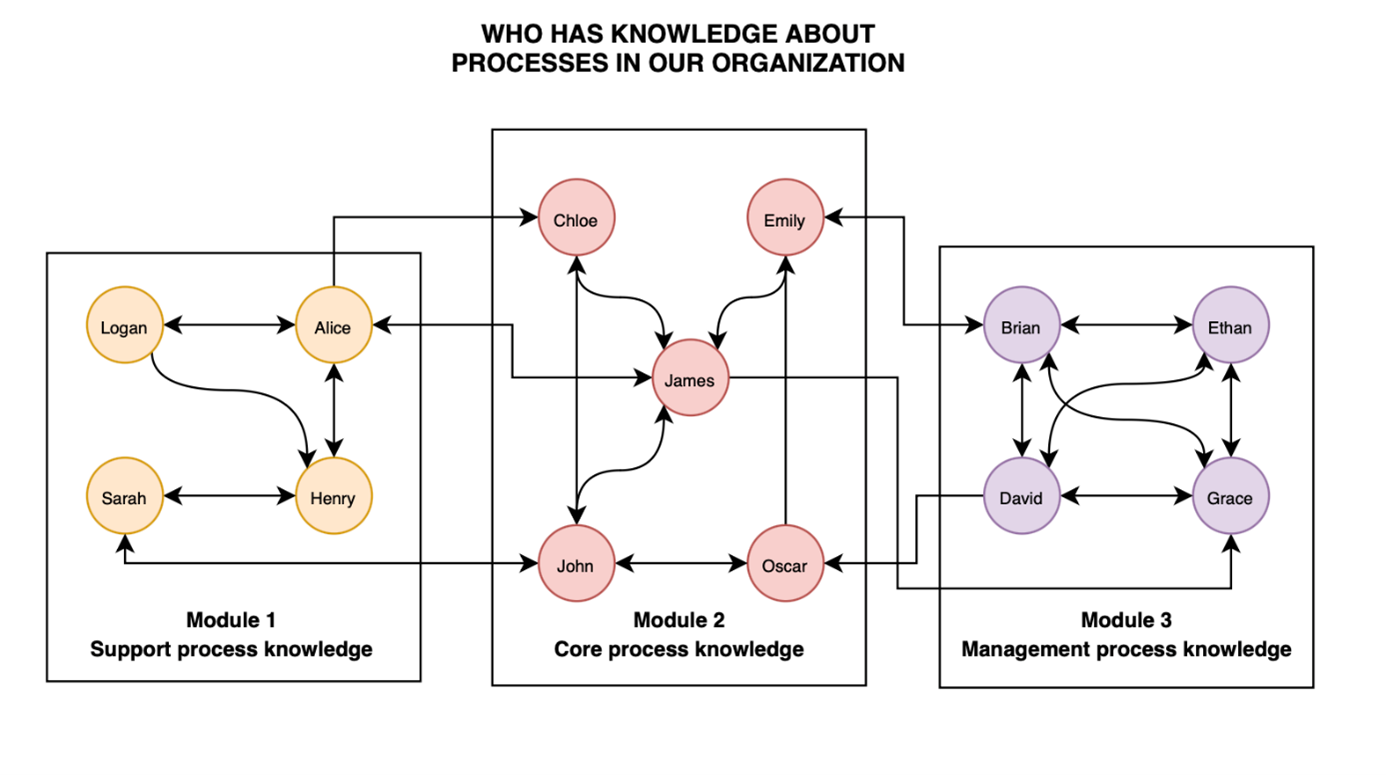
Fig. 3 An example of a modular network, where employees may be group into modules,
which cooperating can mutually exchange their specialized knowledge on some topics
Source: Own elaboration
To sum up, all essential differences between centralized, decentralized and modular way of information organization in management knowledge system, are presented into table:
|
Feature/Network |
Centralized |
Decentralized |
Modular |
|
Organization |
One main node. |
Disperse into more |
Autonomous modules |
|
Failure rate |
Lack of crucial component makes network unable |
Removing one of the nodes, does not |
Failure of module can be influence |
|
Integrality of knowledge |
All knowledge comes |
Different sources |
Specialized modules, which manage some part of knowledge and share them in organization. |
|
Typical use |
Large companies, |
Basic social networks, open-source systems. |
Complex organisation, which |

Fig. 4 Partial map of the Internet based on 24 November 2003 data. Each line is drawn between two nodes, representing two IP addresses and their origin (Asia Pacific -Red; Europe/Middle East/Central Asia/Africa -Green; North America -Blue; Latin American and Caribbean -Yellow; RFC1918 IP Addresses -Cyan; Unknown -White).
Source: https://www.opte.org/the-internet